定义数据库对象
Oracle数据库对象(表、视图和索引)可以很容易的移植到Microsoft SQL
Server上,这是因为两个数据库都基本遵循SQL-92标准,该标准承认对象定义。把Oracle SQL的表、索引和视图的定义转换为SQL
Server的表、索引和视图的定义只需要做相对简单的语法改变。下表指出了Oracle和Microsoft SQL
Server之间的数据库对象的某些不同之处。 类别 Microsoft
SQServer Oracle
列数 1024 254 行尺寸 8060 byte, 外加16 byte用来指向每一个text或者image列 无限制 (每行只允许有一个long或者long raw) 最大行数 无限制 无限制 BLOB类型存储 行中存储一个16-byte 指针。数据存储在其他数据页。 每表一个long或者long raw。必须在行的结尾。数据存储在行的同一个块里。 分簇表索引 每表一个 每表一个(index-organized tables) 未分簇的表索引 每表249 无限制 在单一索引中的最大索引列数 16 16 索引中列值的最大长度 900 bytes ½ block 表名约定 [[[server.]database.]owner.] [schema.]table_name 视图名约定 [[[server.]database.]owner.] [schema.]table_name 索引名约定 [[[server.]database.]owner.] [schema.]table_name 假设你是从一个Oracle脚本或者程序开始的,该脚本或者程序用来创建你的数据库对象。拷贝你的脚本或者程序并且进行如下修改。这些修改将在本部分的其他地方加以讨论。该例子是从示例应用程序脚本Oratable.sql和Sstable.sql中截取的: 1. 确保数据库对象标识遵循Microsoft SQL Server命名法则。你可能只需要修改索引的名字。 2. 修改数据存储参数使之能在SQL Server下工作。如果你使用RAID,就不需要任何存储参数了。 3. 修改Oracle约束定义使之能在SQL Server中工作。如果需要的话,创建一个触发器以支持外部键DELETE
CASCADE语句。如果表跨数据库的话,使用触发器来增强外部键的关系。 4. 修改CREATE INDEX语句以利用分簇的索引。 5. 使用数据转换服务来创建新的CREATE TABLE语句。回顾该语句,注意Oracle数据类型是如何映射到SQL
Server数据类型上的。 6. 清除所有的CREATE SEQUENCE语句。在CREATE TABLE或者ALTER
TABLE语句中使用同等列来替换顺序的使用。 7. 如果需要的话,修改CREATE VIEW语句。 8. 清除所有对同义字的引用。 9. 评估对Microsoft SQL Server临时表的使用和其在你的应用程序中的用处。 10.把所有的Oracle的CREATE TABLE…AS SELECT命令改为SQL Server的SELECT…INTO语句。 11.评估潜在的对用户定义规则、数据类型和缺省的使用。 数据对象标识符 下表比较了Oracle和Microsoft SQL Server是如何处理对象标识符的。在许多情况下,当移植到SQL
Server上时,你不需要改变对象的名字。 Oracle Microsoft
SQL Server 1-30 字符长度。 1-128 Unicode字符长度。 标识符的名称必须用:字母、包含文字数字的字符、或者字符_, $, 和 #开头 标识符名称可以用:字母数字字符、或者_开头,实际上可以用任何字符开头。 如果标识符用空格开头,或者包含了不是_、@、#、或者$的字符,你必须用[](定界符)包围标识符名称 如果一个对象用下面这些字符开头: 表空间名必须唯一. 数据库名必须唯一 标识符名在用户账号(计划,Schema)范围内必须唯一。 标识符名在数据库用户账号范围内必须唯一 列名在表和视图范围内必须唯一。 列名在表和视图范围内必须唯一。 索引名在用户账号(Schema)范围内必须唯一。 索引名在数据库表名范围内必须唯一 修饰表名 当访问存在于你的用户账号中的表时,该表可以简单的通过未经限制的表名来选中。访问其他Oracle计划中的表就需要把该计划的名字作为前缀加到表名上,两者之间用点号(.)隔开。Oracle同义字可以提供更高的位置透明度。 涉及到表时,Microsoft SQL Server采用一种不同的方法。因为一个SQL
Server登录账号可以在多个数据库中用同一个名字创建一个表,所以采用下面的方法来访问表和视图:[[数据库名字]所有者名字]表名] 用……访问一个表 Oracle Microsoft
SQServer 你的用户账号 其他模式(schema) 这是一些为Microsoft SQL Server表和视图命名的指导方针: 同时,这些数据库的其他用户可以有同样名字的对象: 因此,建议你在引用数据库对象时包含所有者的名字。如果应用程序有多个数据库,建议你再把数据库名字也包含在引用中。如果查询跨越多个服务器,还要包括服务器名。 SQL Server的每个连接都有一个当前数据库上下文,这是在登录时用USE语句设置的。例如,假设有下面的场景: 可以在数据库和表名之间加两个点号来省略对象的所有者名。例如,如果应用程序引用STUDENT_DB..STUDENT,SQL
Server就做如下搜寻: 1. STUDENT_DB.current_user.STUDENT 2. STUDENT_DB.DBO.STUDENT 如果应用程序一次只使用一个数据库,在做对象引用时省略数据库名字,这样的话,该应用程序可以方便的用于其他数据库。所有的对象引用都隐含的访问当前所用的数据库。这对于你要想在同一台服务器上维持一个测试数据库和一个产品数据库时很有用 创建表 因为Oracle和SQL Server都支持SQL-92条目级(entry-level)的关于标识RDBMS对象的协议,CREATE
TABLE的语法是相似的。 Oracle Microsoft
SQ CREATE
TABLE CREATE TABLE
[server.][database.][owner.] table_name
Oracle数据库对象名字是不分大小写的。在Microsoft SQL
Server中,数据库对象的名字可以是大小写敏感的,这要看安装时的设置。 当SQL Server第一次设置的时候,缺省的排序顺序是字典顺序,区分大小写。(可以用SQL
ServerSetup来做不同的设置)因为Oracle对象的名字总是唯一的,你在把数据库对象移植到SQL
Server上时不会遇到任何的麻烦。建议你把Oracle和SQL
Server中的所有的表和列的名字都写成大写的以避免万一有用户安装了区分大小写的SQL Server时出问题。 表和索引存储参数 对于Microsoft SQL Server,使用RAID通常可以简化数据库对象的放置。在表的结构中集成了一个SQL
Server的分簇的索引,就像一个Oracle索引组织表一样。 Oracle Microsoft
SQ CREATE TABLE DEPT_ADMIN.DEPT
( CREATE TABLE
USER_DB.DEPT_ADMIN.DEPT ( 用SELECT语句创建表 使用Oracle,一个表可以用任何有效的SELECT命令创建。Microsoft SQL
Server提供了同样的功能,但是语法不一样。 Oracle Microsoft
SQ CREATE TABLE STUDENTBACKUP AS
SELECT * FROM STUDENT SELECT * INTO STUDENTBACKUP
要SELECT…INTO能够起作用,必须将使用该程序的数据库的选项select
into/bulkcopy设定为true。(数据库所有者可以用SQL Server Enterprise
Manager或者Transact-SQL的sp_dboption系统存储程序来设置该选项)。用sp_helpdb系统存储过程来检查数据库的状态。如果select
into/bulkcopy未设定为true,你仍然可以用SELECT语句拷贝到临时表中,就像下面这样: SELECT * INTO #student_backup FROM user_db.student_admin.student 当用SELECT.. INTO语句来创建新的表时,其参考的完整性定义不会转换到新的表中。 将select
into/bulkcopy设定为true的要求可能会使移植的过程变得复杂。如果你必须用SELECT语句拷贝数据到表中,请首先创建表,然后再用INSERT
INTO…SELECT语句来载入该表。对于Oracle和SQL Server来说,语法是一样的,也不需要设置任何数据库选项。 视图 在Microsoft SQL Server中创建视图的语法同Oracle一样。 Oracle Microsoft
SQ CREATE [OR REPLACE] [FORCE |
CREATE VIEW
[owner.]view_name SQL
Server视图要求表必须存在,并且视图的所有者必须有访问在SELECT语句中标明的数据库的权限(同Oracle中的FORCE选项相似)。 缺省情况下,不会检查视图上的数据修改语句来判定受影响的行是否在视图的范围内。要检查所有的修改,请使用WITH CHECK
OPTION。对于WITH CHECK OPTION主要的不同之处在于,Oracle将其作为约束来定义,而SQL
Server不是。此外,两者的功能是一样的。 在定义视图的时候,Oracle提供了一个WITH READ ONLY选项。SQL
Server应用程序可以用仅向视图用户提供SELECT权限的方法来达到同样的结果。 SQL Server和Oracle视图都支持派生列、使用数学表达式、函数以及常量表达式。SQL Server的某些特殊的不同之处是: 当一个视图是和一个外部连接一起定义的,并且查询限定在外部接合点的内部表上时,SQL
Server和Oracle的结果会有所不同。在大多数情况下,Oracle视图很容易转化为SQL Server视图。 Oracle Microsoft
SQ CREATE VIEW
STUDENT_ADMIN.STUDENT_GPA CREATE VIEW
STUDENT_ADMIN.STUDENT_GPA 索引 Microsoft SQL
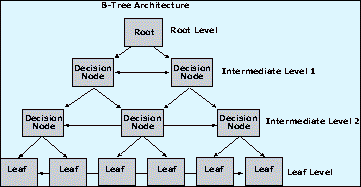
Server提供了分簇和未分簇的索引结构。这些索引是由来自于一个叫做B-tree的树型结构中的页构成的(同Oracle中的B-tree索引结构相似)。起始页(“根”级)说明了表中值的范围。“根”级页中的每一个范围指向其他页(判断节点),该节点包含了表中值的更小的范围。以此类推,该节点又可以指向其他的判断节点,这样就缩小了搜索的范围。树型结构的最后一级叫做“叶”级。 分簇的索引 分簇的索引在Oracle中是以索引组织表的形式实现的。一个分簇的索引是一个物理的包含在一个表中的索引。表和索引分享同一块存储空间。分簇的索引按索引顺序物理的重排数据行,建立起中间判断节点。索引的“叶”页包含了真实的表数据。这个结构允许每个表只有一个分簇的索引。Microsoft
SQL Server为表自动的创建一个分簇的索引,无论该表设置了PRIMARY KEY还是UNIQUE约束。分簇的索引对下面这些是有用的: SELECT * FROM STUDENT WHERE GRAD_DATE BETWEEN '1/1/97' AND '12/31/97' SELECT * FROM STUDENT WHERE LNAME = 'SMITH' 例如,在STUDENT表上,在ssn的主键上包含一个未分簇的索引是很有用的,而分簇的索引可以在lname、fname(last
name、first name)上创建,因为这是一种常用的区分学生的方法。 删除和重建一个分簇的索引在SQL
Server中是一种很普通的重新组织表的技术。这是一种确保数据页在磁盘上是连续的以及重建表中的一些可用空间的简单的方法。这同Oracle中导出、删除以及导入一个表是很相似的。 一个SQL
Server分簇的索引与Oracle的簇在根本上是不一样的。一个Oracle的簇。一个Oracle的簇是两个或者更多的表的物理集合,它们分享同一个数据块,使用一个公共的列来作为簇键。SQL
Server没有与Oracle簇相似的结构。 作为一个普遍的原则,在表上定义一个分簇的索引将提高SQL
Server的性能并且加强空间管理。如果你不知道对于给定表的查询和更新模式,你可以在主键上创建一个分簇的索引。 下表摘录自示例应用程序的源代码。请注意SQL Server“簇”化索引的使用。 Oracle Microsoft
SQ CREATE TABLE STUDENT_ADMIN.GRADE
( CREATE TABLE STUDENT_ADMIN.GRADE
( 未分簇的索引 在未分簇的索引中,索引数据和表数据在物理上是分开的,并且表中的行并不是按顺序存储在索引中的。你可以把Oracle索引定义移植到Microsoft
SQL
Server未分簇的索引定义上(就像在下表中显示的一样)。可是,考虑到性能的缘故,你可能希望选择表的其中一个索引把它创建为分簇的索引。 Oracle Microsoft
SQ CREATE
INDEX CREATE NONCLUSTERED
INDEX 索引语法和命名 在Oracle中,一个索引的名字在一个用户账号中是唯一的。在In Microsoft SQL
Server,一个索引的名字在一个表名中必须是唯一的,但是不必在用户名和数据库名中唯一。因此,在SQL
Server中创建或者删除索引时,你必须说明表名和索引名。另外,SQL Server的DROP INDEX语句可以一次删除多个索引。 Oracle Microsoft SQL
CREATE [UNIQUE] INDEX
[schema].index_name DROP INDEX ABC; CREATE [UNIQUE] [CLUSTERED |
NONCLUSTERED] DROP INDEX
USER_DB.STUDENT.DEMO_IDX,
USER_DB.GRADE.DEMO_IDX
索引数据存储参数 Microsoft SQL
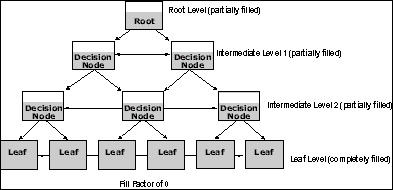
Server功能选项中的FILLFACTOR选项在很多方面与Oracle中的PCTFREE变量相似。当表的尺寸增加的时候,索引页也相应改变以容纳新的数据。索引必须自己进行重新组合以容纳新的数据。只有在创建索引的时候,才使用填充参数百分比,而且在这之后也不加以维护。 FILLFACTOR选项(0-100)控制着在创建索引时应该留下多少空间。如果没有表明参数,就使用缺省参数,该参数是0,表示将完全填充索引的“叶”页,并且在每个判断节点为至少一个条目留下空间(如果有两个条目,则表示是一个不唯一的“簇”化索引)。 一个较低的填充因数将会减少索引页的分裂,但是会增加B-tree结构的层数。较高的填充因数能更有效的使用索引页空间,只需要较少的磁盘I/O来访问索引数据,并且将会减少B-tree结构的层数。 PAD_INDEX选项表示,填充因数也将应用到判断节点页上,就象要用在索引的数据页上一样。 虽然在 Oracle中可能需要调整PCTFREE参数以优化性能。但是在CREATE
INDEX语句中很少使用FILLFACTOR参数。填充因数是为性能优化而提供的。但是它仅仅在一个表上为已有数据创建索引时才有用,并且只有在你能精确的预测数据在未来的变化时才有用。 如果你将Oracle中的PCTFREE参数设为0,可以考虑将它设为100。这在表中不会发生数据输入和修改(只读表)时是很有用的。如果填充因数设为100,服务器将创建这样一个索引,它的每一页都是完全填满的。 忽略重复的关键字 无论在Oracle还是在Microsoft SQL
Server中,用户都不能在一个或者一些唯一索引的列中输入重复的值。这样做将会产生一个错误消息。然而,SQL
Server允许开发人员选择INSERT或者UPDATE语句将如何处理这个错误。 如果在CREATE
INDEX语句中使用了IGNORE_DUP_KEY,并且执行了一个创建重复的关键字的INSERT或者UPDATE语句,SQL
Server将给出一个警告信息,并且忽略重复行。如果没有使用IGNORE_DUP_KEY,SQL
Server将给出一个错误信息,并且后滚整个INSERT语句。如果需要了解关于这个选项的更多信息,请参看SQL Server联机手册。 使用临时表 一个Oracle应用程序也许必须创建一个暂时存在的表。应用程序必须确保在某个时候删除所有为此目的创建的表。如果应用程序不这样做,那么表空间将很快变得混乱,难以管理。 Microsoft SQL
Server提供了临时表数据库对象,这个表就是为上面提到的目的创建的。这样的表总是在tempdb数据库中创建的。表的名字决定了该表在tempdb数据库中要存在多长时间。 表名 描述 #table_name 这个本地临时表只在用户会话或者创建它的过程的生命期内存在。在用户退出登录或者创建它的过程完成以后,该表自动删除。该表不能在多个用户之间共享。其它数据库用户不能访问该表。在该表上不能赋予或者撤消许可。 ##table_name 该表也典型的存在于用户会话或者创建它的过程的生命期内。但该表可以被多个用户共享。在最后一个引用它的用户会话断开以后,该表自动删除。所有其它数据库的用户都可以访问该表。在该表上不能赋予或者撤消许可。 可以为临时表定义索引。但是只能在那些在tempdb中显明的创建的表上创建视图,这些表的名字前不加#或者##前缀。下面的例子显示了一个临时表和相应的索引的创建。当用户退出的时候,表和索引就自动删除了。 SELECT SUM(ISNULL(TUITION_PAID,0))
SUM_PAID, MAJOR INTO #SUM_STUDENT FROM USER_DB.STUDENT_ADMIN.STUDENT
GROUP BY MAJOR CREATE UNIQUE INDEX SUM STUDENT IDX ON
#SUM STUDENT (MAJOR) 在你的程序代码中使用临时表,你可以发现它的好处。 数据类型 同Oracle比起来,Microsoft SQL Server在数据库类型的选择上更强大。在Oracle和SQL
Server数据类型之间有很多可能的转换方式。我们建议你使用DTS向导来自动创建新的CREATE
TABLE语句。需要的时候,你还可以修改它。 Oracle Microsoft
SQ CHAR 推荐使用char。
char类型的列比varchar列的访问速度要稍微快一点,因为char列使用一个固定的存储长度。 VARCHAR2 和 LONG varchar或者 text. (如果在你的Oracle列中数据值的长度小于或等于8000 bytes
,使用varchar;否则,你必须使用text。) RAW 和 LONG RAW varbinary或者 image. (如果在你的Oracle列中数据值的长度小于或等于8000
bytes,使用varbinary;否则,你必须使用image。)
NUMBER 如果整数在1到255之间,
使用tinyint. DATE datetime. ROWID 使用identity列类型 CURRVAL, NEXTVAL 使用identity列类型, 以及@@IDENTITY, IDENT_SEED(), 和IDENT_INCR()
函数。 SYSDATE GETDATE(). USER USER. 使用Unicode数据 Unicode规范定义了一个编码方案,该方案使用单一编码方式为全世界范围内业务上使用的所有字符编码。所有的计算机都能使用单一的Unicode编码把Unicode数据中的位模式转换成为字符。这个方案确保了在所有的计算机上,同样的位模式转换为同样的字符。数据可以自由的从一个数据库或者一台计算机传送到另一个上面,而不用考虑接受系统能否把位模式正确的转换成字符。 使用一个字节来表示字符的方法有一个问题,就是这种数据类型只能表示256个字符。这样就为不同的语言产生了多个编码规范(或者叫做代码页)。这样做也不可能处理日文或者韩文这样有上千个字符的语言。 Microsoft SQL Server把在SQL
Server中安装了代码页的字符的位模式转换成char,varchar,或者text类型的列。客户端则使用操作系统安装的代码页来解释字符的位模式。现在有很多不同的代码页。有些字符只在某些代码页上才有,在别的代码页上就没有。某些字符在某些代码页上定义为一种位模式,在另外一些代码页上又定义为另一种位模式。如果你要建立一个必须处理各种语言的国际系统时,为那些满足语言要求或者多个国家的计算机挑选代码页就变得非常困难。同样,在和一个使用不同代码页的系统连接时,确保每一台计算机都能正确的实现字符转换也非常困难。 Unicode规范使用双字节编码方案解决了这个问题。使用双字节编码,就有足够的空间来覆盖最广泛使用的商业语言了。因为所有的Unicode系统都采用同样的位模式来代表所有的字符,在从一个系统转移到另一个系统的时候,就不会发生字符转换不正确的问题了。 在SQL
Server中,nchat,nvarchar和ntext数据类型支持Unicode数据。如果需要了解关于SQL
Server数据类型的更多信息,请参看SQL Server联机手册。 用户定义数据类型 可以为model数据库或者单用户数据库创建用户定义数据类型。如果是为model定义用户定义数据类型,则该数据类型可以被定义之后所有新创建的用户数据库使用。用户定义数据类型是通过sp_addtype系统存储程序来定义的。如果需要了解更多信息,请参看SQL
Server联机手册。 你可以在CREATE TABLE和ALTER
TABLE语句中使用用户定义数据类型,并且为它绑定缺省方式和规则。如果在表的创建过程使用用户定义数据类型时显明的定义了nullability,则它比在数据定义时定义的nullability优先级高。 下例显示了如何创建用户定义数据类型。参数是用户类型名字,数据类型和nullability。 sp_addtype gender_type, 'varchar(1)',
'not null' go 这个能力对于解决与Oracle表创建脚本移植到SQL
Server上相关的问题是很有用的。例如,要增加一个Oracle的DATE数据类型是非常简单的。 sp_addtype date,
datetime 这个功能不能用在那些需要变长度的数据类型上,例如Oracle数据类型NUMBER。如果这样做,系统将会返回一个错误信息,告诉你需要标明数据长度。 sp_addtype varchar2, varchar Go Msg 15091, Level 16, State 1 You must specify a length with this
physical type. Microsoft Timestamp列 timestamp列使得BROWSE模式修改和游标修改操作更有效。timestamp是这样一个数据类型,含有timestamp列的行有输入或者修改操作时,该数据类型自动修改。 timestamp列中的值不是按照实际的日期和时间存储的,而是作为binary(8)或者varbinary(8)存储的,这个值表示表中一行发生的事件的频率。一个表只能有一个timestamp列。 如果要了解更多信息,请参看SQL Server联机手册。 对象级许可 Microsoft SQL
Server对象特权可以向任何其他数据库用户、数据库组以及public角色授予、拒绝授予、和撤消。SQL
Server不允许对象的所有者授予其他用户、组或者public角色ALTER TABLE和CREATE
INDEX特权,这一点与Oracle不同。这些特权必须被对象所有者保留。 GRANT语句创建一个安全系统的入口许可,该许可允许当前数据库中的一个用户可以操作当前数据库中的数据,或者执行特定的Transact-SQL语句。GRANT语句的语法在Oracle和SQL
Server中是一样的。 DENY语句在安全系统中创建一个条目,拒绝当前数据库中的一个安全账号的许可,并且禁止该安全账号继承自该账号所属的组或者角色成员的许可。Oracle中没有DENY语句。REVOKE语句清除以前授予给当前数据库中一个用户的许可或者拒绝其许可。 Oracle Microsoft
SQ GRANT {ALL
[PRIVILEGES][column_list] | permission_list
[column_list]} GRANT REVOKE [GRANT OPTION
FOR] DENY 在Oracle中,REFERENCES特权只能授予用户。SQL
Server则允许把该特权授予数据库用户和数据库组。INSERT、UPDATE、DELETE和SELECT特权的授予在Oracle和SQL
Server中以同样的方式处理。 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||